Using Changelogs and Streams to Solve Blockchain Data Challenges
How Goldsky leverages data streaming fundamentals to process onchain data the right way. • 5 mins

Principal Software Engineer
Mirror pipelines are a new way to think about blockchain data. Teams get data pushed into their infrastructure, as opposed to traditional API polling architectures. Goldsky developed a unique, zero-copy, realtime streaming system that can work with a variety of databases, used by companies like Dora, Aave, and OP Labs.
When we started building Mirror last year, we immediately knew that we wanted to use data streaming technologies like Apache Kafka and Apache Flink as a foundation. Theoretically, the blockchain could be modelled very well as a traditional Kafka changelog. However, we didn’t realize how well they actually work for the blockchain data.
In this post, we’ll illustrate how several concepts from the world of data streaming and stream processing can be applied to Web3 data.
Decentralized Ledger 🤝 Distributed Log
Modern distributed log technologies like Apache Kafka have several key qualities:
- Data is immutable. Once an event is written to the log, it’s not possible to change it. It can be deleted (through a retention policy) or compacted, but never changed.
- All events in a single partition are strictly ordered. Each event has a monotonically increasing offset number.
Sounds familiar? Because it is — blockchains have the same qualities! Blocks are immutable. They are also strictly ordered (hence the “chain”) and have a monotonically increasing block number.
💡 Of course, there is an exception to this rule: reorgs. We’ll cover it in a bit!
So, it’s only natural to take blockchain data and put it into a distributed log like Apache Kafka, for example, with a topic per dataset (blocks, transactions, logs, receipts, etc.). Raw blockchain data has a fairly straightforward schema, and it can benefit from a strict format like Apache Avro or Protocol Buffers (backed by a schema registry, of course).
And that’s precisely how Goldsky’s data platform is designed!
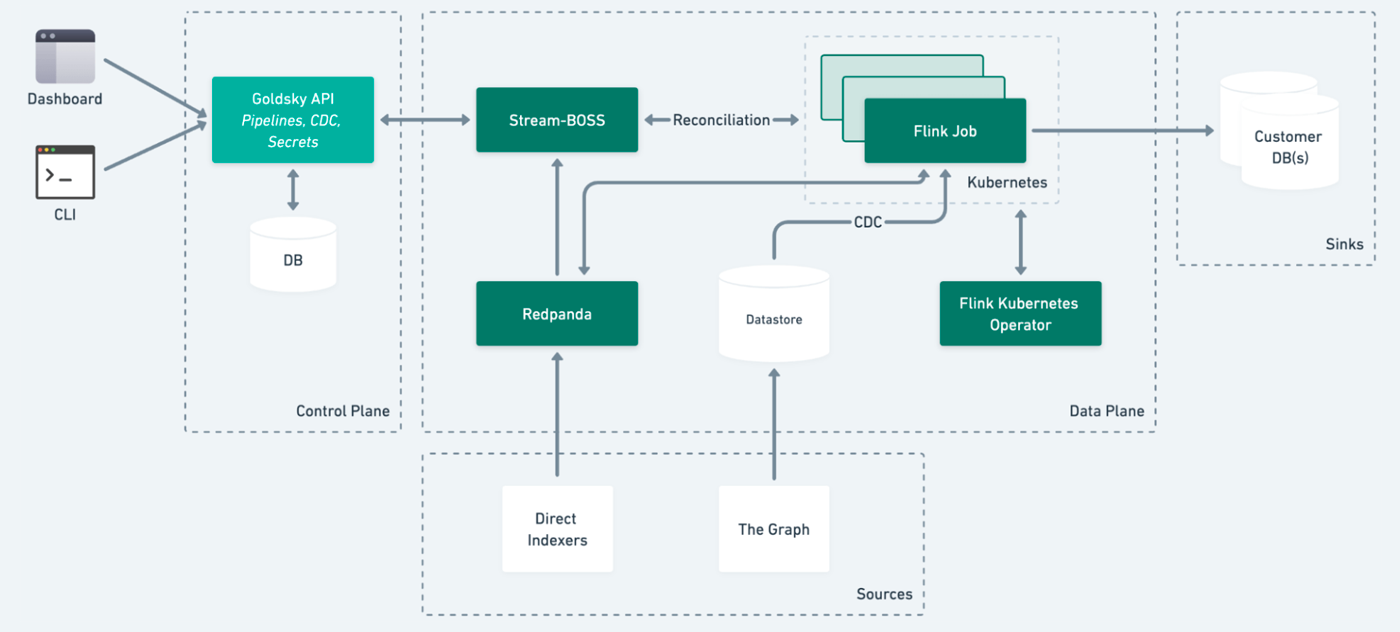
Stream Processing for Any Use Case
When all your data is available as topics in Apache Kafka, it’s very easy to apply stream processing with a tool like Apache Flink to project, filter, or aggregate data in any way.
For example, you can filter data using a certain contract address. Or build a Top 10 aggregation of the wallet balances. Or even perform complex pattern recognition!
It’s also very easy to start from the genesis block by consuming data in a topic from the earliest offset. Or you can decide to process data from the current point in time by using the latest offset.
And you can even do it with SQL! Flink SQL is a powerful SQL dialect that supports most of Flink’s functionality.
However, things can get very complicated very quickly. Typically, mature streaming deployment would require a dedicated team to manage the resources, data freshness, QA checks, and downstream consumers. We built Mirror as a serverless solution that allows users to just specify a YAML file to get started.
goldsky pipeline create --name eth-decoded-logs --definition '
# A simple example that starts a firehose of all data from
# our decoded ethereum logs dataset
sources:
- name: ethereum.decoded_logs
version: 1.0.0
type: dataset
startAt: latest
referenceName: ethereum.decoded_logs
transforms: []
sinks:
- type: postgres
table: eth_logs
schema: goldsky
secretName: API_POSTGRES_CREDENTIALS
sourceStreamName: ethereum.decoded_logs
'Dealing With Reorgs
Earlier, we said that the blockchains are immutable. It’s almost true, but sometimes (depending on the blockchain), a reorg can happen, which, in practice, means that the current data for a certain block should be retracted and corrected.
And again, there is a very similar concept of retractions in the data streaming world! For example, when a windowed aggregation is performed, it’s typical to configure a watermark which can control how late an event can arrive. So we could model a reorg as a late event, and Flink will perform retractions and update results automatically! Since the finality time is known for each chain, we don’t need to guess when choosing the watermark.
A different, more generic approach is to model every data stream as a changelog stream. In this case, whenever a reorg happens, we just need to re-emit all data for a block that’s no longer valid with a DELETE marker. It’ll be propagated to all defined transformations and sinks. That’s why when using Goldsky and a database like Postgres, Rockset, or ClickHouse, you don’t need to think about reorgs, they’re handled for you.
Tying Subgraphs into Mirror
Subgraphs are a big source of semantic data in the blockchain world, and contains a lot of valuable abstractions, often written by protocol authors themselves. We wanted to allow our users to take advantage of Mirror without having to rewrite everything with SQL transforms, using subgraphs as a data source.
We realized subgraphs could be deconstructed into a changelog stream using Change Data Capture techniques, which allows the modelling of all changes as INSERTs, UPDATEs or DELETEs.
And since all records have primary keys, it’s easy to leverage upserts to maintain the latest version of each entity in the destination database. For example, when you mirror subgraph data to Elasticsearch or Rockset with Goldsky, you automatically get the latest version of each entity. So subgraphs with many updates don’t take up a lot of storage.
Beyond Onchain
The synergy between data streaming and decentralized data is clear, and Mirror is flexible enough to support a wide range of data sources and sinks.
Loading off-chain data, getting a price feed, or loading NFT metadata are all examples of data enrichment, a very well-known problem in the data streaming space.
Since we already did the upfront work of modelling the blockchain and snapshotting data into streams, an incredible ecosystem of streaming connectors in the community makes it easy to deliver raw or transformed data to any datastore with low latency.
The possibilities are endless, and we’re very excited about what Goldsky’s architecture can provide for builders in the future. 🚀
Realtime Data Streaming with Goldsky
Goldsky’s mission is to unleash the full potential of Web3 data.
We’re solving complex data engineering challenges so that builders can focus on what matters most — building transformational applications and delivering value to users.
Sign up for full access to Goldsky’s realtime data streaming platform today, and be sure to give us a follow on Twitter for the latest news and announcements.