Introducing Goldsky Edge: a multi-region RPC endpoint built on open source
Meet Edge, our new RPC endpoint backed by a global edge network

Software Engineer, Software Engineer
In 2024, we were building an EVM indexer and battling the same RPC problems every web3 team deals with: providers going down, stale data, rate limits at the worst possible moment.
So we built our own proxy to fix it, and eventually open-sourced it as eRPC. Teams like Circle and Morpho started contributing and using it. Then Goldsky acquired us.
Today we're shipping Goldsky Edge, a managed version of eRPC that runs on a global edge network. This post shares more about how we got here, what Edge does under the hood, and a few things we learned along the way.
TL;DR: Goldsky Edge is a single RPC endpoint that leverages a multi-region architecture to route requests across 8+ global regions, validates responses via cross-node consensus, and fails over within milliseconds. Flat $5/million requests with no upcharges. Supports most EVM chains and 60+ standard JSON-RPC methods.
Why we built an open-source EVM RPC proxy
July 2024 was when we first started building eRPC. Like many products, it was initially built to solve a problem we were facing ourselves.
At the time, we were working on an EVM indexer called Flair (actually a Goldsky competitor at the time!). We kept running into annoying problems with our RPC stack: reliability was poor, resiliency was low, failovers were nonexistent, and speed was inconsistent. Every RPC provider promises fast, reliable, and cheap. But almost all of them let you down at least 10% of the time.
The typical workaround is to either stick with one provider and hope for the best, or you put a basic round-robin proxy in front of a few and pretend that's high availability and redundancy. But a proxy that actually understands the EVM (knows what a re-org means for cached data, knows RPC call methods behave differently across providers, knows a node can be "up" but still serving stale blocks, etc.) didn't exist.
So we built an internal version for ourselves. It was a proxy layer that handled caching, failovers, rate limiting, and smart batching to help keep Flair running smoothly.
And it worked pretty well! Well enough that we began talking to other teams in the space. Unsurprisingly, almost everyone building serious web3 infrastructure had either built their own internal RPC proxy or was suffering without one.
The problem was universal, but nobody had open-sourced a proper solution. Why did this matter? Because to be fully comfortable, this tool needed to be open-source so that you could run it next to your infra while having full control over the configs.
That's when we decided to release eRPC as an open-source project. We put it out in August 2024 and started sharing it with people in the ecosystem.
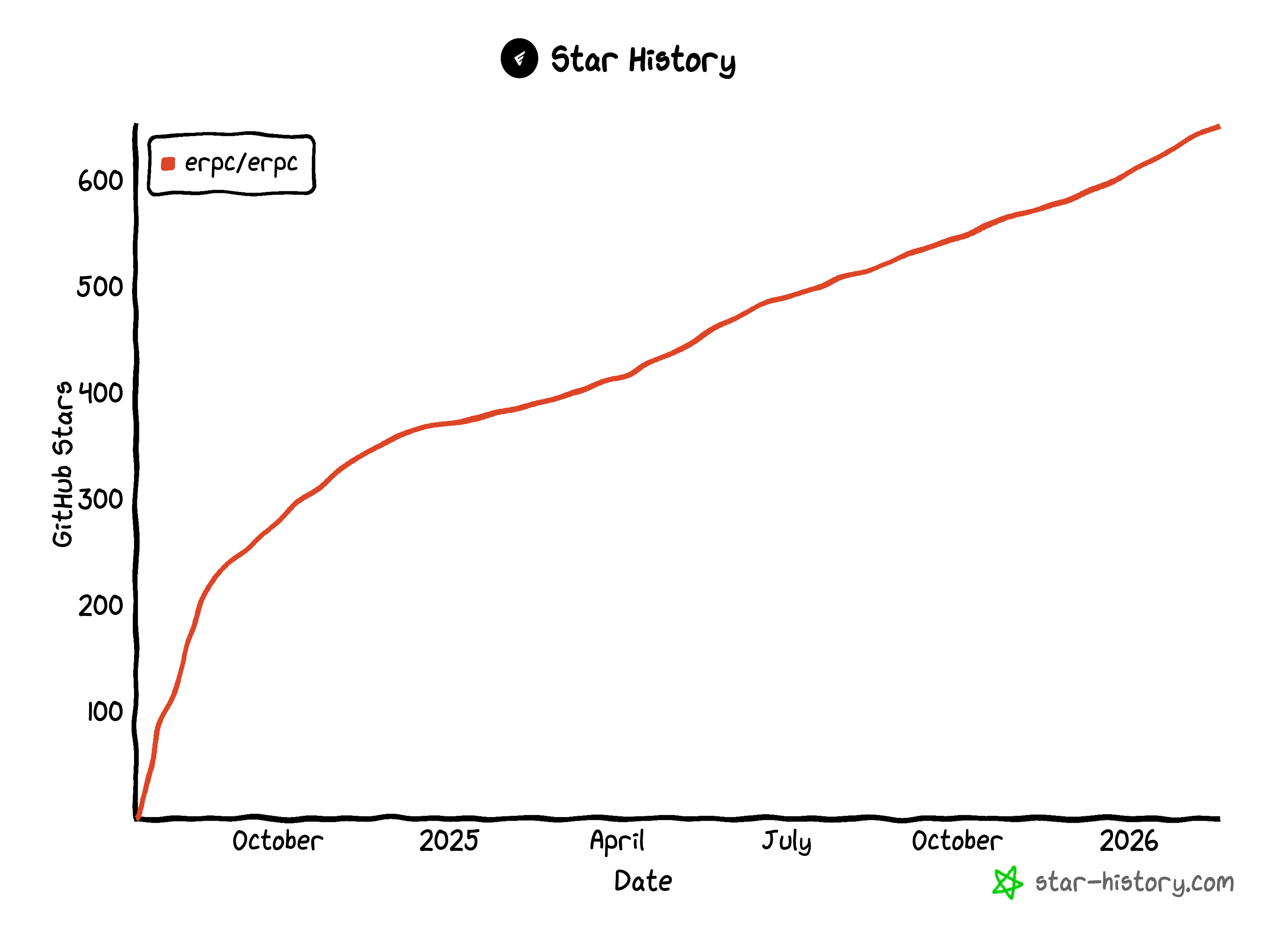
Adoption came faster than we expected. We quickly saw forks, clones, and PRs from the likes of Polygon, Circle, Morpho, Succinct, Nethermind, and more.
One of those people was Jeff at Goldsky. We reached out to him early on, and he was interested; Goldsky had already built their own internal solution for the same problem.
A few months later, in December 2024, Jeff came back to us. Goldsky used a similar architecture for their indexing product and he saw potential synergies between what we were building and what they needed.
We hopped on a call.
Then another. And another.
The conversations kept going because the alignment was obvious: we were solving the same problem from different angles. Joining together meant we were going to solve much harder problems together at a larger scale.
In January 2025, Goldsky officially acquired us.
eRPC continues to remain fully open-source and maintained.
Every blockchain team rebuilds the same flawed RPC layer
If you've built anything on EVM chains, you've dealt with RPC issues that quietly ruins your Thursday afternoon.
Your indexer silently falls behind because a provider started returning stale block heights. Your frontend hangs for 2 seconds because eth_call routed to a node on the other side of the planet. Your eth_getLogs response comes back missing half the events, and you don't find out until a user files a bug report (or worse, you face revenue loss).
Most teams deal with this by duct-taping together multiple providers, writing custom retry logic, and building health-check scripts that page them at ungodly hours. Some teams build an internal proxy layer (like we did). Well-funded teams hire a person whose entire job is managing RPC infrastructure.
None of these are great solutions. They're just varying degrees of coping with the same underlying issue: the standard RPC endpoint is a single point of failure that doesn't know anything about the requests it's serving.
And here's the part that surprised us: it doesn't matter how good a provider's reputation is. During reorgs, even "benchmark trusted" providers return wrong data.
No single upstream is immune, even those with internal layers of proxies and node redundancies. There had to be a smart middleware layer to handle this. Something that validates before it returns.
How Edge handles RPC caching, routing, failover, and validation
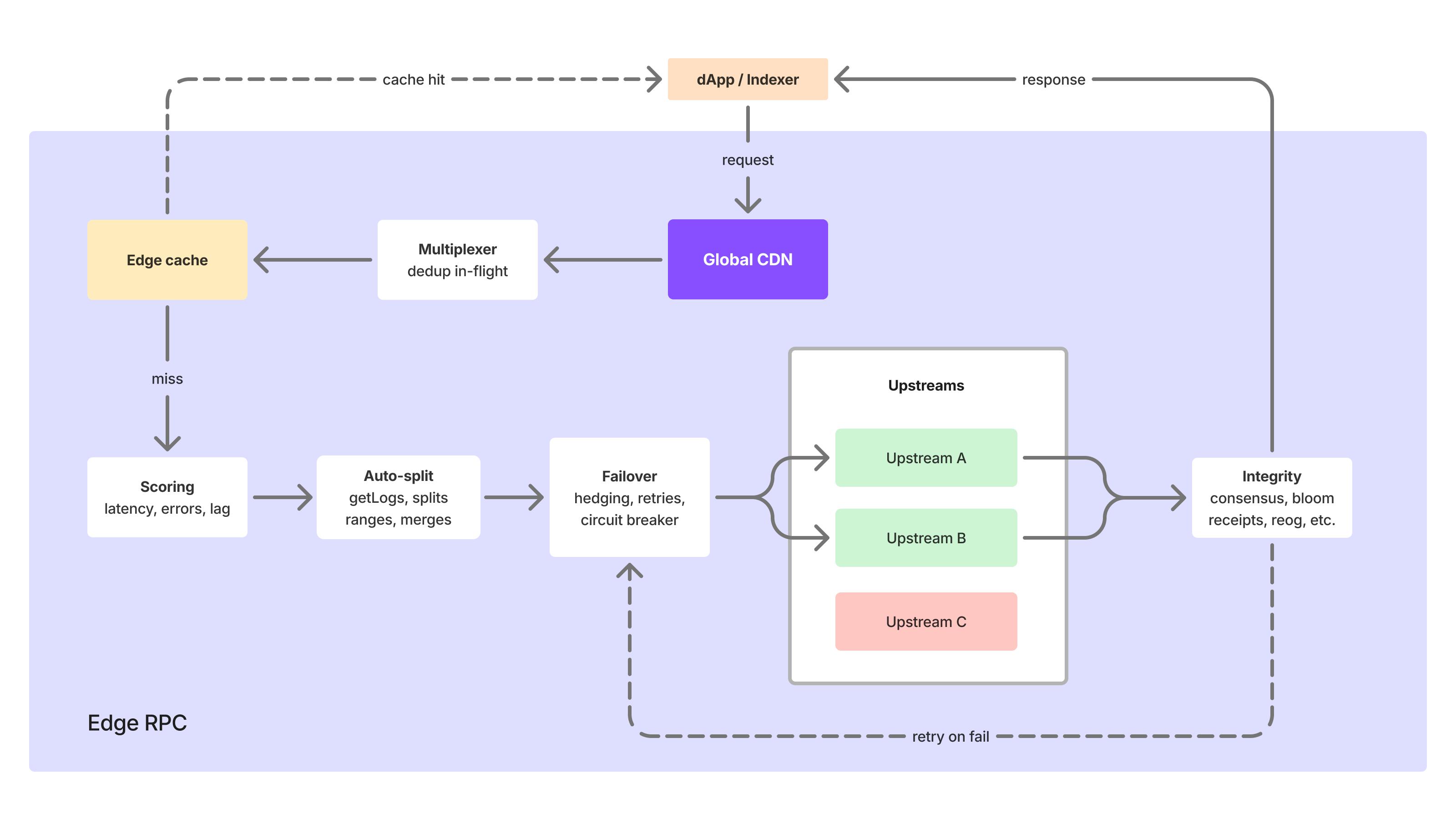
Edge sits between your application and the upstream RPC providers. It's a proxy layer, functioning with the reliability of an AWS Network Load Balancer, but calling it that undersells what's happening inside. Here's a simplification of what happens when your app makes an RPC call:
Global edge routing: your request hits the nearest node
- We access 200+ nodes across multiple availability zones in 8+ regions. When your app makes an RPC call, it routes to the closest one automatically.
- For common queries (latest block number, recent transactions, etc. that make up roughly 30% of requests), the response comes straight from cache. We're seeing 7ms average latency on these.
Finality-aware caching: the cache checks if it already has the answer
- Caching is finality-aware, not just TTL-based. This distinction matters more than it sounds.
- We aggressively cache finalized data (blocks that the chain has confirmed won't change). But we never cache stale chain-tip data. The caching layer understands where the finality boundary is and behaves differently on each side of it.
- When the cache is hit, you get a response in single-digit milliseconds and the request never touches an upstream provider or makes a round trip.
Multiplexing: identical requests get merged
- Concurrent identical requests are merged into a single upstream call. When 50 users request the same block at the same time, Edge calls the upstream once and fans out the response.
- This reduces redundant RPC calls and keeps costs down without any configuration. It means you benefit from the scale across Goldsky’s thousands of customers, and own internal 10B+ monthly query workload.
Adaptive node scoring: Edge picks the best upstream for your RPC call method
- Behind the edge, we maintain connections to multiple upstream providers for every chain.
- Every upstream is continuously scored using an adaptive AI mechanism: P90 latency, error rate, block head lag (how far behind the chain tip it is), and more. Whichever node is performing best is naturally prioritized.
- Routing is method-aware. Your requests go to the best-performing provider for that specific method.
eth_getLogsmight route differently thaneth_getBalancebecause different providers have different strengths.
Auto-splitting: large queries get broken up and stitched back together
- Large
eth_getLogsblock ranges get automatically split into smaller sub-requests, executed in parallel across multiple upstreams, and reassembled into a complete response. - Without this, you hit range limit errors: nodes refuse requests bigger than they can handle, and every provider's limit is wildly different. One can handle 10,000 blocks while another might only allow 500. Auto-splitting learns each upstream's actual threshold and breaks the request down accordingly, so you never have to worry about individual node limitations.
Cross-node consensus: responses are validated before they reach you
- Edge validates responses using cross-node consensus. We call multiple nodes, compare the results, and only return data we're confident is correct.
- This feature was controversial for us. It adds latency. It adds cost. But we stand by it because our priority ordering is clear: integrity first, latency second, cost third. A fast response that's wrong is worse than a slow one that's correct.
- Beyond consensus, our integrity module catches a subtler problem: silently incomplete data. An
eth_getLogsresponse can come back missing events with no error at all. Edge validates responses using bloom filter checks, block height tracking, and range enforcement to catch what consensus alone can't. - We're working on novel approaches to achieve high data quality without the latency tradeoff -- more on this soon :)
Automatic failover: if anything goes wrong, you don't notice
- When a node fails mid-request, you don't notice. Edge switches to a healthy one within the same request cycle. Your app gets the expected response without seeing a 500.
- We use hedged requests for latency-sensitive calls – these are sent to multiple nodes in parallel, and we return the fastest response.
- Exponential backoff handles transient errors.
- Circuit breakers isolate providers that are having a bad day so their problems don't become yours.
Writes and transaction submission
- Edge can also submit signed transactions via
eth_sendRawTransactionwith intelligent routing to healthy nodes. - Write requests get the same failover and routing intelligence that reads do.
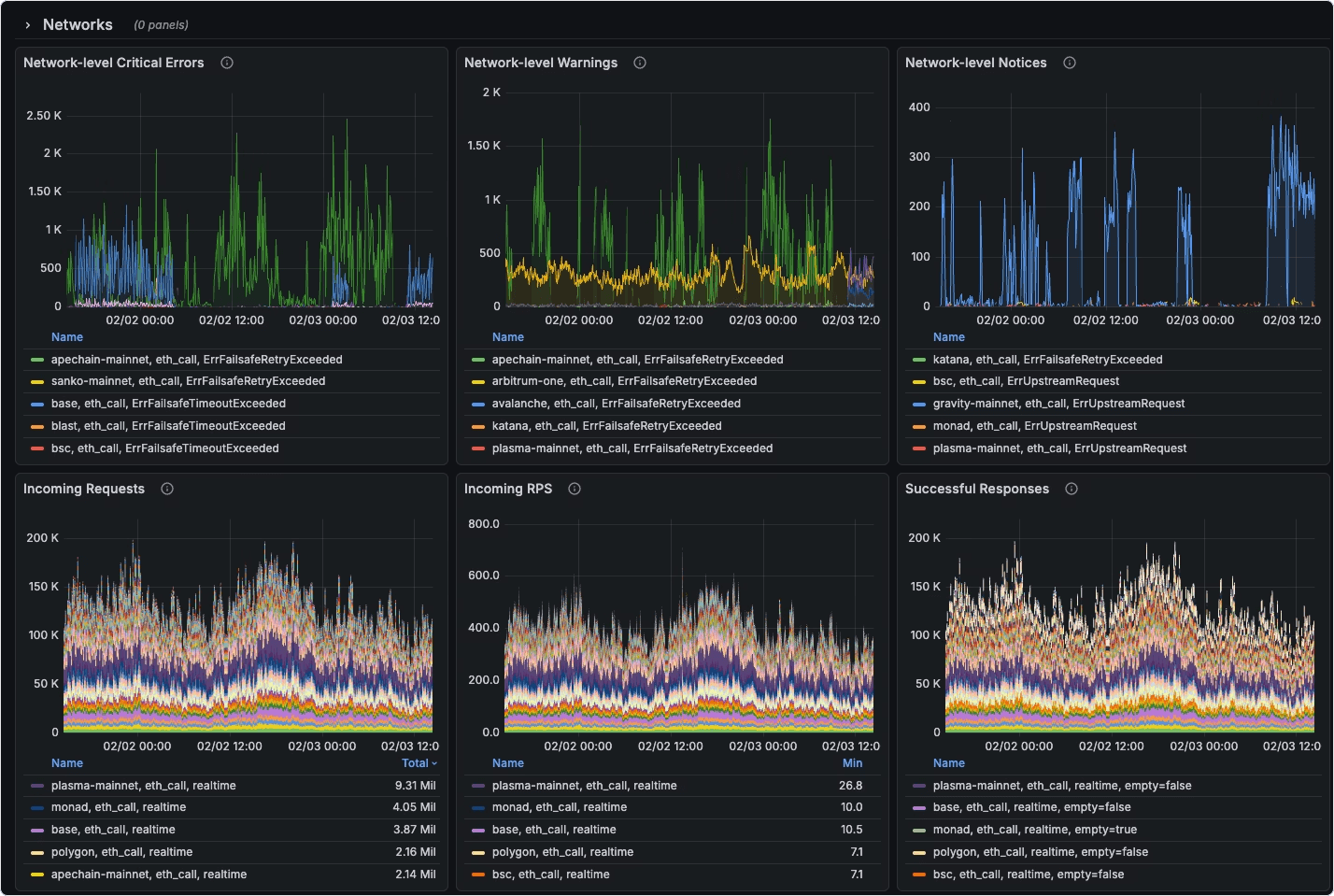
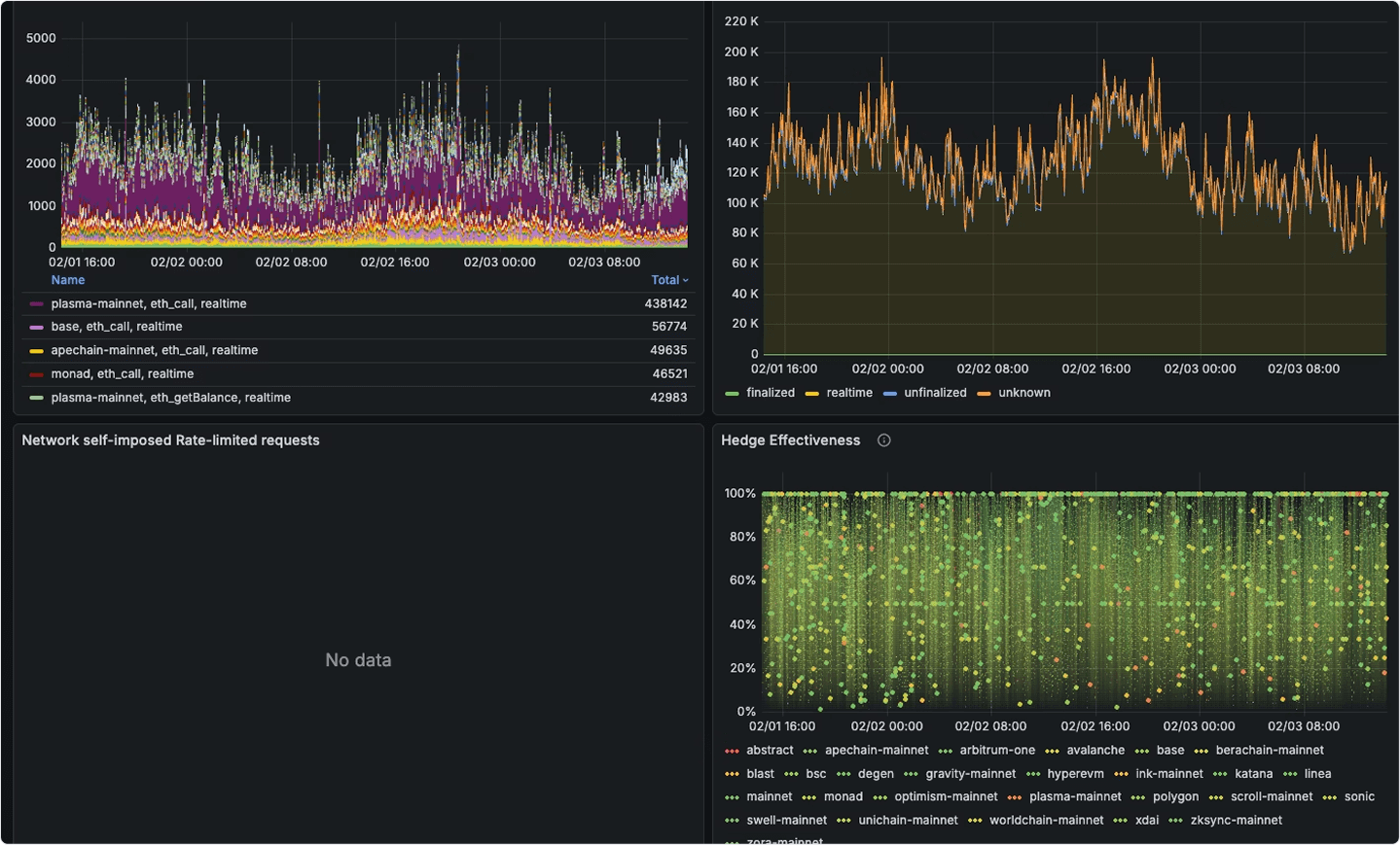
RPC monitor: built-in observability
All of this is visible from day one. Edge endpoints come with an advanced Grafana dashboard with request volume, latency percentiles, error rates, upstream provider health, etc. out of the box. We also surface detailed error logs with full context: which method, which chain, which upstream, what went wrong.
RPC provider quirks and data integrity
We'd be lying if we said we building Edge was smooth sailing. Far from it.
There were moments we nearly threw in the towel. We battled complex, cascading memory pressure bugs. And our consensus feature, the one we were most committed to, sometimes caused more problems than it solved. Not because our logic was wrong, but because some chains were in a broken state and nodes had no way to agree. We pushed through those and made the system more robust each time.
A few hard-won lessons
Our first caching layer was too aggressive. We cached responses that could become stale during chain reorgs, and served them to indexers that needed the canonical chain data. We had to build reorg-aware cache invalidation to track the chain tip and purge entries when blocks get replaced. This is the kind of thing that works fine 99.99% of the time and catastrophically fails during the 0.01% that matters most. Reorgs on Polygon and HyperEVM are particularly brutal, where providers silently return stale data with no indication anything is wrong.
This led to an unexpected rabbit hole: block cache corruption. It's not just "bad RPC data". There's a complex interplay of cache delays, reorgs, consensus timing, and downstream indexing assumptions that all compound on each other. It led us to rethink the entire validation architecture from scratch.
Consensus doesn't help if everyone is confidently incorrect. Sometimes four nodes agree on a block, and they're all wrong. During reorgs, multiple providers can serve the same orphaned block with full confidence. You have to layer in finality awareness, track the canonical chain state independently, and be willing to invalidate data that passed consensus seconds ago.
We also underestimated how much variation there is between providers for the same method. For example, one provider's eth_getLogs implementation might handle a 10,000-block range without flinching while another returns a rate limit error at 1,000 blocks. Our auto-splitting logic had to get smarter about learning each upstream's actual limits rather than assuming uniform behavior. Much of this is undocumented and can only be learned through experience with hundreds of billions of queries to catch every edge case.
Multiplexing sounded straightforward until we ran into edge cases around request timing windows and error propagation. If 200 users request the same block at the same time and the upstream returns an error, you need to be careful about how you propagate that failure. Retrying once and fanning out the result is different from fanning out the error.
No-nonsense RPC pricing
One thing that frustrated us about the RPC market is pricing complexity. Most RPC providers use compute unit (CU) systems where an eth_getLogs call might cost 75 CUs for example and a eth_blockNumber costs 1 CU. You can't predict your bill without knowing your exact method distribution, which changes as your application and user traffic evolves.
Edge is a flat $5 per million requests
And every method costs the same. No compute unit multipliers, tiered method pricing, or hidden surcharges. You'll know your exact cost based on how many requests you've sent.
User experience is the #1 deciding factor for every single decision at Goldsky, and pricing is no exception. If we're routing your requests efficiently and caching some expensive ones, the cost to us per request flattens out. Passing that simplicity through to pricing just makes sense. Unlike providers that charge different rates for eth_*, debug_* and trace_* methods, Edge treats every call the same: archive queries, trace calls, log fetches, they’re all the same price.
Volume discounts
Volume discounts kick in at 500M+ requests/month. Chat with us if you're at that scale for even better pricing.
eRPC stays open-source while Edge builds on it at scale
Edge is built on eRPC, which will continue to be maintained as open-source under Apache 2.0. The core proxy logic (like routing, caching, failover, circuit breaking) is all in the public repo, making it easy to integrate with tools like Terraform.
Edge adds the managed infrastructure layer on top: the global CDN, monitoring stack, upstream provider relationships, and the operational work of keeping it running at scale.
Because eRPC is open-source, you can also run it as a sidecar inside your own indexer. You get full context on validation, consensus, and retry logic, with complete control and visibility into what's happening because it’s an open box.
If you want to self-host, you can. If you want us to run it for you, that's Edge. The open-source project gets better because the managed product funds development, and the managed product gets better because the open-source community finds bugs and contributes features. It's a flywheel that's already spinning – community PRs from teams like Circle and Polygon have directly improved Edge, and Edge usage surfaces bugs that get fixed upstream in eRPC.
Try Edge RPC in a few clicks
- Create your endpoint in Goldsky
- Or read through the Edge RPC docs to learn more
If you're running infra at scale and want to talk about volume pricing or dedicated CDN nodes, reach out to our team.
We built this because we needed it. We think you might like it too.
Aram & Kasra