The Web3 Developer's Journey: From RPC → Indexing → ETL
When you're building onchain, all roads eventually lead to modern data pipelines. • 6 mins

Principal Software Engineer
The journey of a Web3 developer is filled with plenty of twists and turns. Every challenge we face while building onchain applications requires a unique approach, and not all solutions are created equally. With the landscape of available tooling changing every day, we've identified the core moments of insight nearly every Web3 developer encounters on their path from basic RPC calls to onchain enlightenment.
In the Beginning, There Was RPC
Simple ETH RPCs are great for managing and syncing nodes. But when it comes to powering user-facing applications, RPCs alone leave a lot to be desired. Designed around the needs of consensus, the ETH RPC API can be challenging to work with for many types of queries we'll commonly encounter.
Sample RPC Call for NFT Collection Data
/*
This approach requires one network request to get the total number of
tokens, then two network requests per token to get owner and metadata.
For a simple collection of 20 NFTs, that's 41 network requests to get
the data to render the web page.
*/
const nftContract = new web3.eth.Contract(contract.abi, contractAddress);
const getTokenUriAndOwner = async (
tokenId: number
): Promise<TokenQueries> => {
const [tokenUri, owner] = await Promise.all([
nftContract.methods.tokenURI(tokenId).call(),
nftContract.methods.ownerOf(tokenId).call()
]);
return { tokenId, tokenUri, owner };
};
const getTokenCount = async (): Promise<number> => {
const latestToken = await nftContract.methods.getLatestTokenId().call();
const latestTokenNumber = parseInt(latestToken, 10);
setLatestTokenId(latestTokenNumber);
return latestTokenNumber;
};
const getPreviousNFTs = useCallback(async (
numberOfNFTs: number,
offset?: number
) => {
const latestTokenNumber = await getTokenCount();
const promises = [];
const startNumber = typeof offset === 'undefined'
? latestTokenNumber
: latestTokenNumber - offset;
const endNumber = Math.max(0, startNumber - numberOfNFTs);
for (let i = startNumber; i > endNumber; i--) {
promises.push(getTokenUriAndOwner(i));
}
const results: TokenQueries[] = await Promise.all(promises);
const mappedResults = results.map((result, index) => {
const encoded = result.tokenUri.split(';base64,')[1];
const json = atob(encoded);
return {
metaData: JSON.parse(json),
tokenId: latestTokenNumber - index - (offset || 0),
owner: result.owner,
} as PrevNFTWithTokenId;
});
setData((d) => mappedResults.concat(d || []));
}, []);For example, if you want to show all NFTs and their owners within a particular collection, many network hops are required and the data processing load in the client can be overwhelming. Additionally, data is often encoded, requiring yet another operation to run in the client while your users are stuck staring at a loading indicator.
In a demo project, we saw page load times upwards of 10 seconds just to display a small collection of about 20 NFTs. Most Web3 developers, including myself, started by building and experimenting after finding the docs for a node-as-a-service company, which steered us towards an RPC-centric approach (and also happens to require using their service). We can get pretty far after learning this workflow, but eventually will run into performance issues and hard-to-read code without much hope for relief.
Indexing to the Rescue?
Once we hit a wall with ETH RPC, the general way forward is to look for a better solution. Most of us will be very excited to discover the power of indexers like subgraphs, which give us better access to nested datasets produced onchain. Indexers can be thought of as "blockchain scrapers," constantly reading new blocks as they come in and allowing devs to extract, transform, and save the data.
Sample Subgraph Query for NFT Collection Data
/*
This approach requires one network request to get all the data needed to
render the page because the hard work was done during indexing.
*/
const GET_TOKENS = gql`
query PreviousTokensQuery {
tokens (orderBy: id, orderDirection:desc) {
tokenId
tokenURI
owner
}
}
`;
const { data: gqlData } = useQuery<TokensQuery>(GET_TOKENS);By proactively shaping the data as blocks arrive, you can generate a read-optimized copy of the blockchain data your app cares about. The most popular indexer at the time of writing is The Graph, which is an open-source indexer used by many projects across the industry. While The Graph stores indexed data in a Postgres database, most folks consume the data directly via a GraphQL API.
Indexers: Solved, but Not Perfect
Even with indexers, there is a lot of engineering work required to keep things running smoothly. At Goldsky, it's taken a lot of time (and code) to get to a place where our subgraphs are stable, fast, and cost-effective at scale. Great indexing requires domain-specific data engineering expertise to perform the necessary optimizations to handle reorg errors, volume spikes, and realtime access to data.
Singular EVM nodes can often lag due to their "eventually consistent" nature and can easily get bogged down by lots of traffic. By load balancing between nodes, caching data when possible, and using Firehose, Goldsky been able to mitigate indexing costs for end users while simultaneously boosting both the speed and the accuracy of indexing.
Building these systems in-house is a lot of work! At Goldsky, we believe that Web3 companies shouldn't have to manage these heavy infra optimizations themselves, when they could be focusing energy on their core product experience.
Indexing Is Just the Tip of the Iceberg
Using Graph nodes almost always entails using an API as the sole mechanism for consuming onchain data. But as projects begin to scale, they tend to need additional flexibility that APIs aren't equipped to provide. Web3 companies often run into these types of scaling issues very early in their evolution.
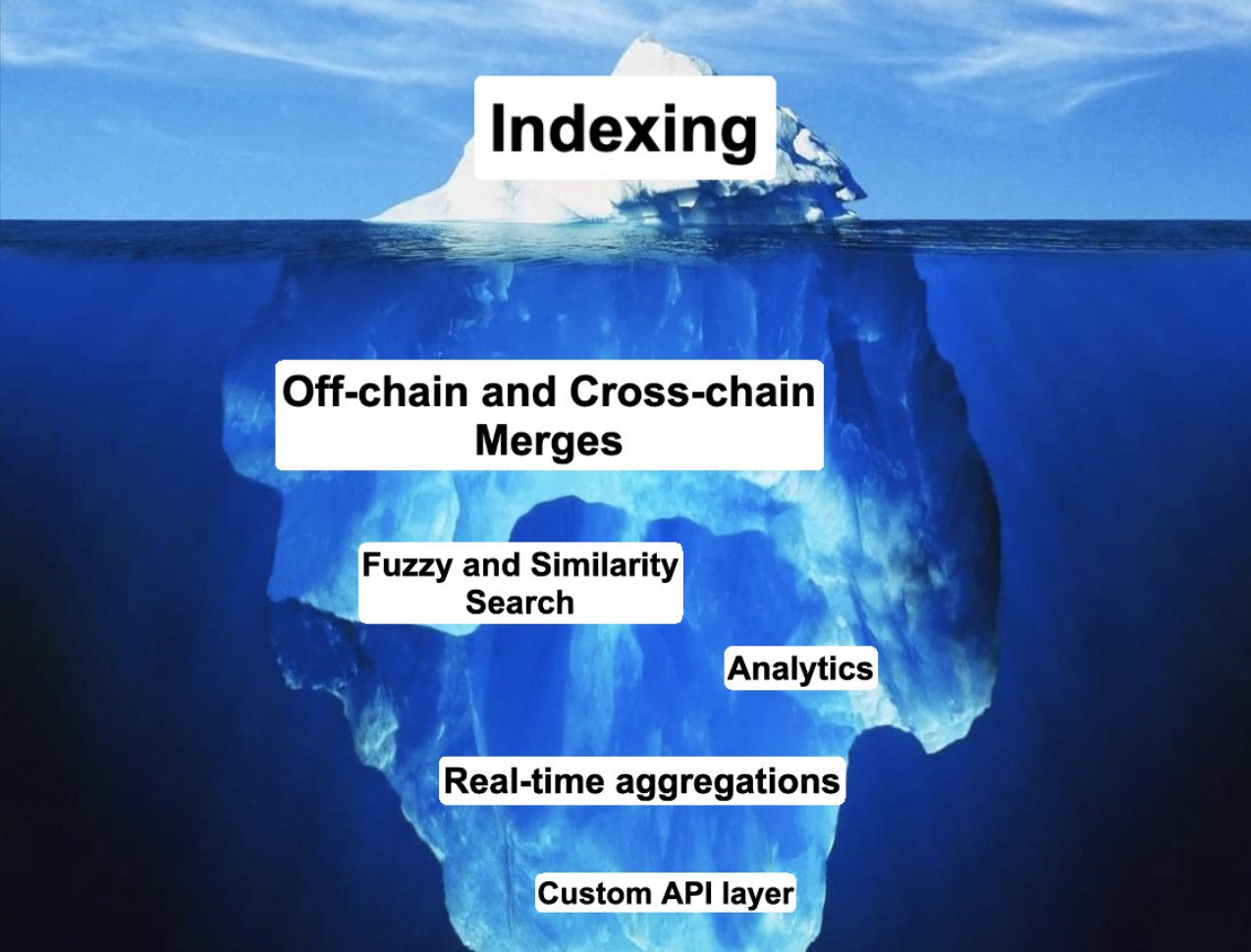
APIs are limited for situations like analytics and optimized queries, leading to development bottlenecks and headaches for the team. Project requirements like search, cross-chain access, or off-chain data mapping can create even more challenges. As business needs grow and diversify, you can soon find yourself in a similar boat to where you were when you first started using RPC nodes — stuck using an API for something it wasn't truly designed for.
Nearly every software company faces scaling challenges as they grow. While Web3 offers a new flavor of these problems, they're not necessarily unique — and because of that, we have a lot of prior art we're able to draw from.
Onchain Data Streaming Pipelines: Limitless Potential
Given the limitations of direct RPC calls and the headache of managing an in-house indexer, Goldsky proposes a new solution. We believe, at the end of the day, that all roads lead to the modern data pipeline.
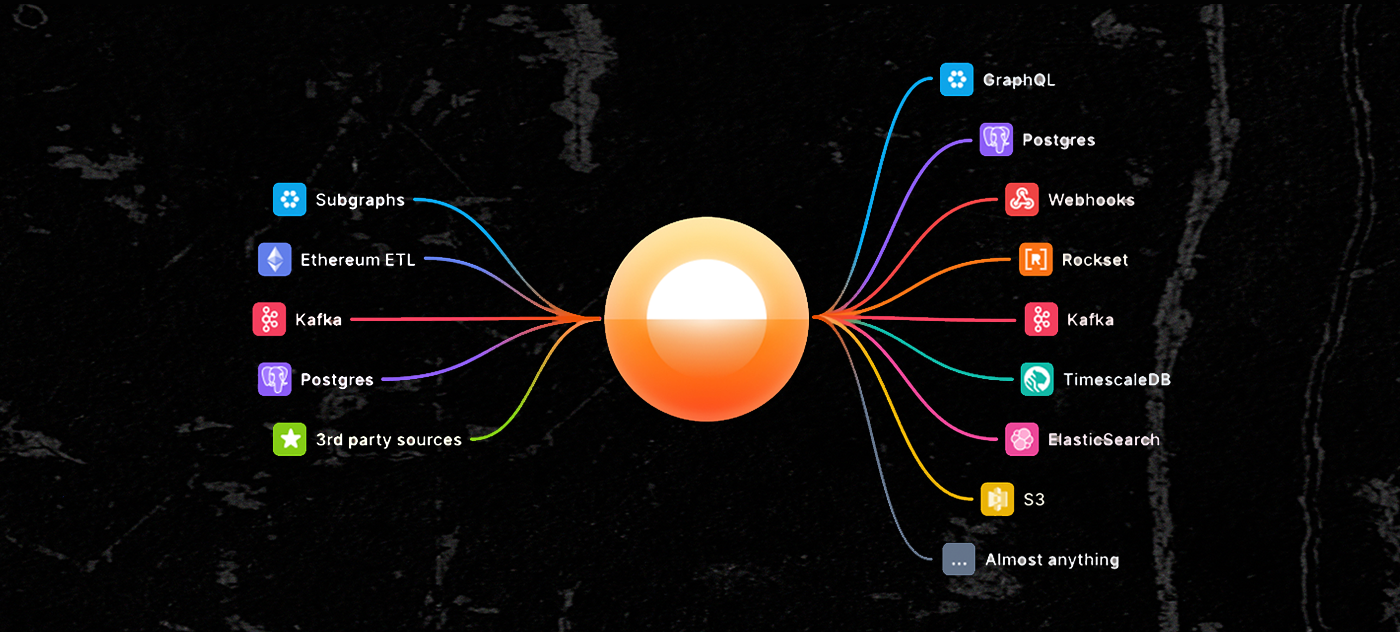
Using modern data engineering tooling such as Apache Kafka and Apache Flink as a foundation, Goldsky is bringing a new, streaming-first approach to onchain data accessibility. Goldsky Mirror allows us to do some very powerful things with onchain data:
Goldsky Mirror
- Gather and merge data from multiple onchain and offchain sources, and integrate new sources as they're available.
- Process, shape, and filter data directly with SQL.
- Sync live data to multiple destinations: Postgres, Elasticsearch, Kafka, s3, and more.
- Query, search, and build with enterprise-grade tooling under the hood.
Reframing onchain data challenges through the lens of the modern data pipeline gives us a brand new look at the full potential of managing, storing, and serving onchain data. When we start to view indexers like subgraphs and Ethereum ETL as data sources in a pipeline versus a final output, we can begin to envision a world of possibilities for tailoring highly-performant datasets for any business use case.
Realtime Data Streaming with Goldsky
Goldsky’s mission is to unleash the full potential of Web3 data.
We’re solving complex data engineering challenges so that builders can focus on what matters most — building transformational applications and delivering value to users.
Sign up for full access to Goldsky’s realtime data streaming platform today, and be sure to give us a follow on Twitter for the latest news and announcements.