Introducing Goldsky Flow: the visual drag-and-drop pipeline builder
Follow @goldskyio on Twitter to stay updated on everything we ship.
Goldsky Flow, our new visual drag-and-drop interface for building Mirror pipelines, is now available to everyone! Now you can create powerful data pipelines in minutes without touching a line of YAML or using the CLI (but no need to ditch the CLI if that's your jam). Here's what you need to know about this new way to ship data.
Build with your eyes
Drag and drop components onto the canvas, configure them with a few clicks, and deploy.
Data sources aplenty
Pull in data from a variety of data source types, with optional configurations.
- Access data from 150+ blockchain networks (and growing weekly)
- Onchain direct indexing datasets
- raw data (e.g. blocks, logs, etc.)
- curated datasets (e.g. ERC-20 transfers)
- Subgraphs
- your existing subgraphs – own the data and bypass GraphQL API limitations
- community subgraphs
- Off-chain data from your Kafka data store or other databases – for easily aggregating on-chain data with off-chain data
You can also combine multiple data sources in the same pipeline into a single unified schema – perfect for multi-chain applications.
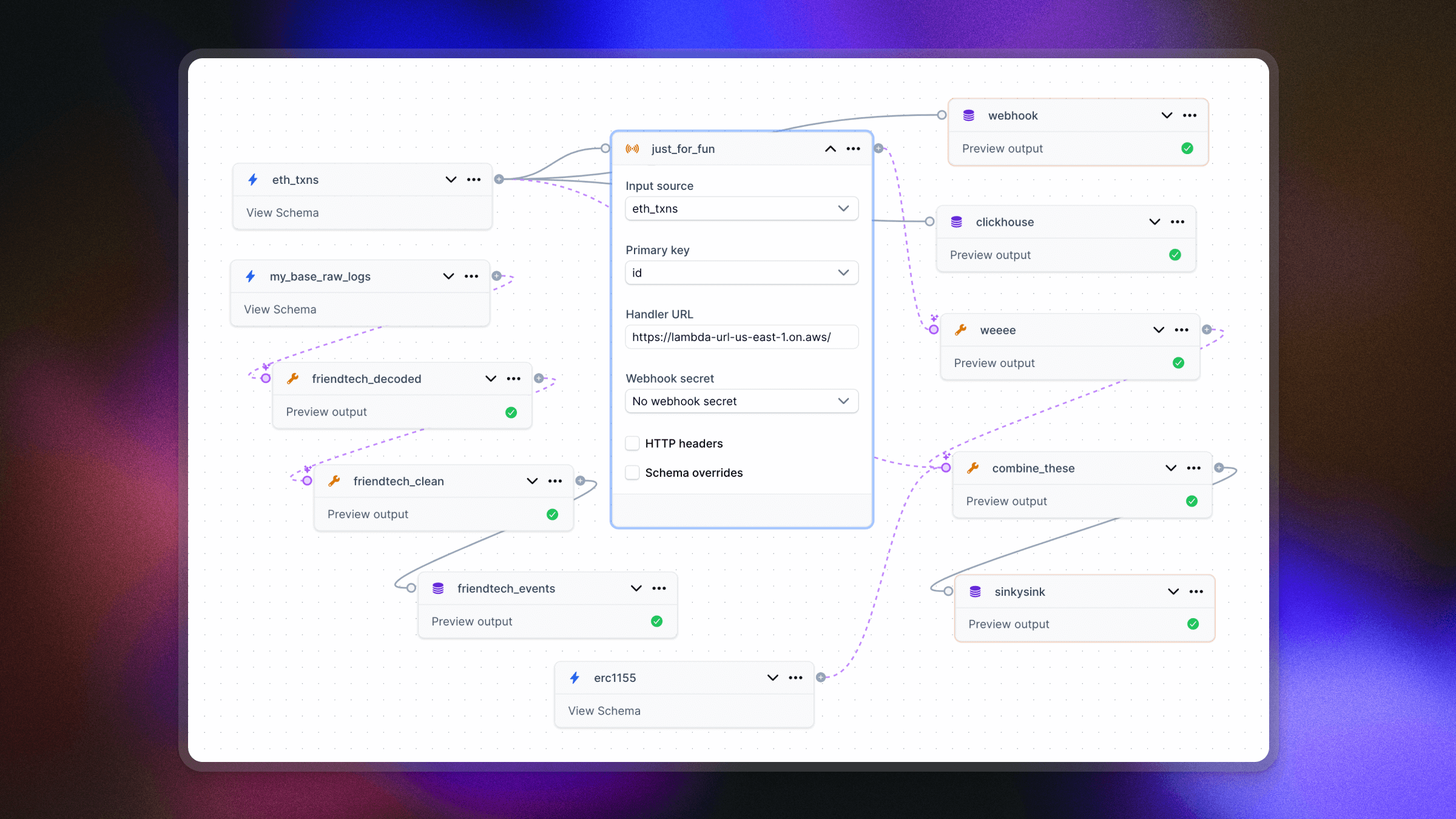
Twist, turn, transform
Shape your data with optional transforms, filters, and aggregations to get it exactly how you want it. Two types of transforms are available:
- SQL transforms: Write standard SQL to manipulate the shape of your data and preview results – all directly within the Goldsky Flow UI.
- External HTTP handler transforms: Send data from your pipeline to external services via HTTP (e.g. AWS Lambda) for processing and return results back into the pipeline. Ideal for using your preferred language or enriching data with third-party APIs (e.g. fetching token prices from Coingecko).
Sink anywhere

Send your data where it needs to go, whether it’s transactional databases like Postgres, real-time analytical databases like ClickHouse, or specialized options like Elasticsearch and Timescale. Use webhooks and Goldsky Channels for flexible routing to AWS S3, SQS, Kafka, and beyond.
Goldsky is sink-agnostic, so you’re not limited to just our directly supported sinks. Don’t see your preferred sink? Just ask – we can likely make it happen.
A few more things:
- Preview pipeline outputs: See samples of your pipeline data within Goldsky Flow. Super handy when you’re working with multiple sources + transforms and you want to quickly iterate on the logic without redeploying the pipeline every time.
- Reorg-aware pipelines: Pipelines are reorg-aware and will automatically update your sinks whenever they occur to keep data consistent. Channel sinks have some nuances, so check the docs for details.
- Secure sink configuration: Goldsky Secrets securely store your database credentials in your Goldsky account so you can manage access without exposing sensitive information in your pipelines or config files.
- Lightning-fast processing: Standard pipelines handle 2,000 rows per second and can be scaled up to process over 100,000 rows per second.
- Extremely low latency: Actual latency depends on how much write speed your database can handle!
Start using Goldsky Flow
Just head to your dashboard and click "New Pipeline" to start building. Dive into the Goldsky Flow documentation for more detailed guides, but we hope that the interface is intuitive enough that you don’t need it.
Whether you’re a visual builder or CLI diehard, we're constantly working on making data pipeline creation even more accessible and powerful, so jump in, test it out, and let us know if you have feedback!