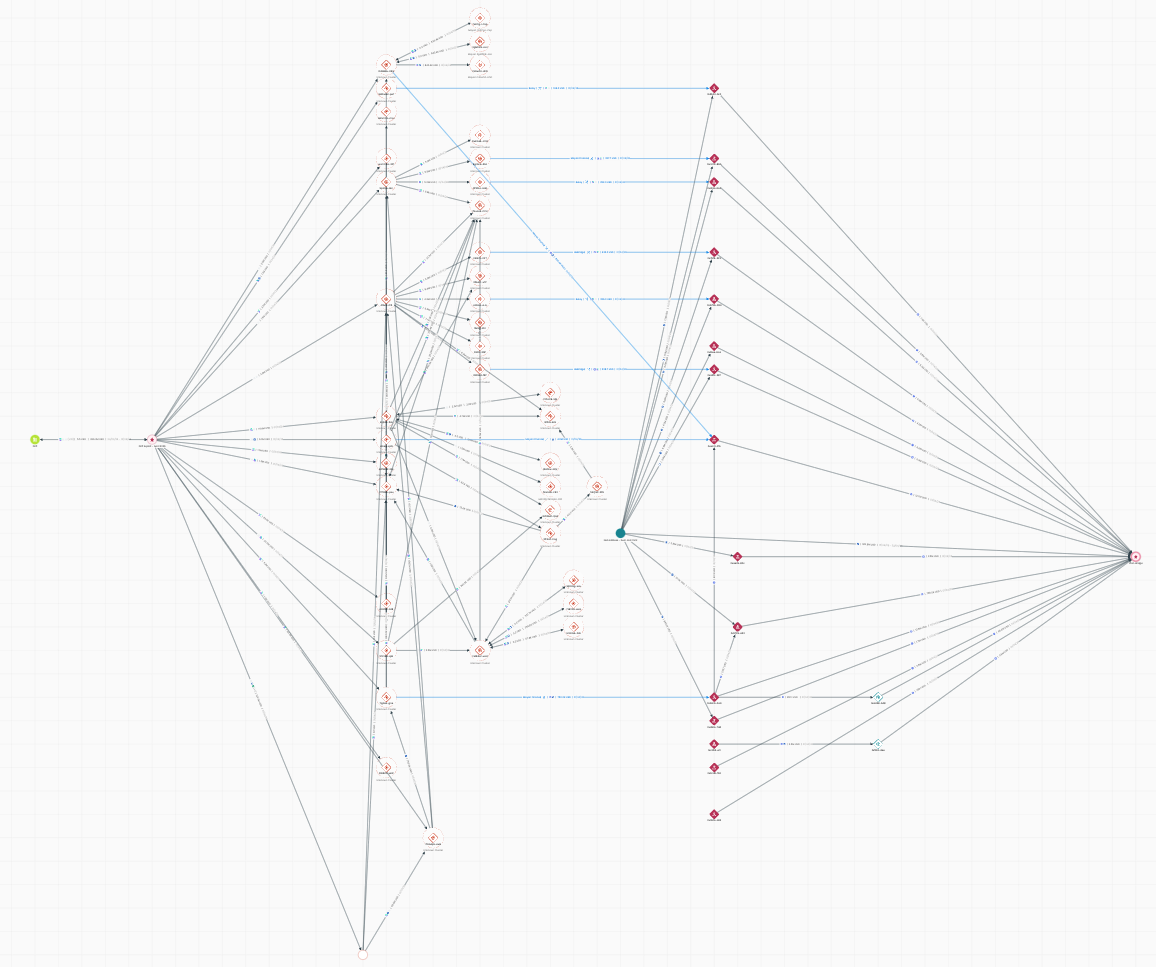
Digital asset lineage: tracking where onchain money came from
Every blockchain records transfers, but not the context behind them. Digital asset lineage keeps information like source of funds, partner attribution, cost basis, and compliance data attached to money as it moves.

Software Engineer
tl;dr: Some of the most valuable facts about onchain money aren’t onchain. Which partner issued a unit of a stablecoin, where a deposit originated, whether funds ever touched a sanctioned address… none of that is written into the transfer.
You can reconstruct these facts, but only by replaying every event in exact order while carrying state for millions of addresses.
Streamling, our open-source runtime, shows how to solve this with a stateful streaming pipeline. An ordered, reorg-aware source feeds a transform that attaches a label at its source, propagates it through every transfer, and maintains a labeled balance for every address. Goldsky provides the ordered, integrity-checked datasets and managed Turbo Pipelines that run it across 150+ chains.
This is the same approach powering partner attribution for Phantom’s $CASH, but the technique generalizes to source of funds, compliance, cost basis, and many other forms of digital asset lineage.
What is digital asset lineage?
Digital asset lineage is the complete history of where a unit of onchain value originated, how it moved, and what additional context remained attached to it over time.
The idea is that you can attach or “tag” additional data to money that the blockchain doesn’t natively record, creating a programmable layer of context that stays attached as the tokens or money continue to be transferred.
That data might be from your own offchain information (outside a blockchain), like who put a stablecoin into circulation. Or it might be derived from onchain activity (but isn’t available as a first-class queryable API), like whether funds trace back to a sanctioned wallet or which bridge they entered through.
A blockchain is excellent at being a ledger. Every transfer records things like:
- how much moved
- which addresses sent and received it
- when it happened
- which token contract was involved
- which transaction included it
But those fields only describe what happened. They don’t preserve the business or operational context surrounding that value as it moves through the system.
The chain records the movement. Digital asset lineage preserves the meaning.
If you've worked with data pipelines, “data lineage” is the same concept – tracking where a piece of data originated and how it changed as it moved through a system. Digital asset lineage is the same principle applied to onchain money.
Why does digital asset lineage matter?
Financial systems need more than a transfer history.
A stablecoin issuer needs to know which partner originally put a unit of supply into circulation. A treasury team needs to preserve cost basis and track AUM as assets move between wallets. A compliance team needs to understand whether funds previously interacted with sanctioned or high-risk addresses.
These are all examples of source of funds: understanding where value originated and what happened to it before it reached its current owner.
This is becomes especially important when onchain assets enter systems that need more context than a wallet balance: stablecoin programs, exchanges, banks, custodians, payment companies, treasury teams, and RWA or tokenized asset platforms.
For them, the question isn’t only “did a transfer happen?” It’s also “what are we actually receiving?”
That’s information a blockchain doesn’t preserve on its own.
A separate system has to reconstruct it by carrying state across every transfer.
| The blockchain records | Digital asset lineage reconstructs |
|---|---|
| Amount transferred | Where the value originated |
| Sender and receiver | Which partner, customer, bridge, or source introduced it |
| Timestamp and block | What path the value took over time |
| Token contract | Whether it interacted with sanctioned or high-risk entities |
| Transaction hash | Your business context that should stay attached as the token moves |
Digital asset lineage turns raw blockchain transfers into information that onchain finance and TradFi (traditional financial) systems can operate on.
How is digital asset lineage different from wallet labels and blockchain analytics?
Blockchain analytics is the broader category of tools and techniques used to turn raw onchain activity into interpretable context. That can include identifying wallets, detecting patterns, scoring risk, tracing funds, address clustering, fund-flow analysis, and more.
Wallet labels and digital asset lineage are two pieces of that larger analytics stack, but they answer different questions.
- A wallet label tells you who an address is
- Digital asset lineage tells you where the tokens/money inside the wallet came from
Tools like Nansen, Arkham, and Etherscan label addresses: Tornado Cash Binance 7 Coinbase Hot Wallet Robinhood Bybit Hacker . These labels describe a static identity tied to the address.
Lineage labels the value itself. The main difference is that the label moves. After all, tokens get used and transferred. When labeled money leaves a wallet, the label leaves with it. It splits when the money splits. It attaches to whoever receives it.
Forensics tools like Chainalysis and Elliptic do both, which is why the two concepts get conflated. They label a source wallet (identity, fixed to the address) and then trace where its funds went (lineage, traveling with the money). When Elliptic flagged the Bybit thief's wallets in 2025, the flag on those addresses was a wallet label. Following that flag to every downstream wallet was lineage.
Think of a wallet label as the number on a mailbox. It tells you whose box it is. But the number itself doesn’t tell you about where any particular letter inside came from.
| Wallet label | Digital asset lineage | |
|---|---|---|
| What it describes | An address's identity | Where a unit of value came from |
| Attached to | The address | The value itself |
| Moves when the money moves | No, it stays on the address | Yes, it travels with the tokens |
| Example | "This wallet is Coinbase" | "These dollars were issued by partner A" |
| Question it answers | Who is this address? | Where did the money come from? |
A wallet label sits on an address. Lineage sits on the money.
How financial institutions use digital asset lineage
Digital asset lineage becomes useful whenever the meaning of money needs to persist after a transfer.
Different teams use it for different reasons, but they’re all answering the same underlying question:
Where did this value come from, and what should still be true about it today?
Some common use cases include:
- tracing stolen or sanctioned funds for compliance and investigations (or tracking if the funds interacted with sanctioned or high-risk addresses)
- preserving cost basis for accounting and treasury as assets move
- attributing stablecoin supply to issuance partners, programs, or the rail that issued it
- understanding source of funds before accepting deposits, redemptions, or settlements
- reconstructing how value moved across wallets, smart contracts, bridges, and chains
- building audit trails for onchain financial products
We’ll illustrate three common use cases.
Following stolen or sanctioned funds
Tracking stolen funds - Elliptic Investigator
When a hacker steals money, they don’t leave the money there.
North Korea’s Lazarus Group for example drained ~$1.5 billion from Bybit in February 2025, then moved the funds through dozens of wallets, assets, exchanges, and bridges within hours in an attempt to obscure the trail.
A compliance or forensics team starts by flagging the attacker’s wallet as the source. From there, lineage carries that label on every dollar as it hops from wallet to wallet, allowing investigators to identify which downstream wallets are now holding “tainted” money.
This is the digital version of a marking stolen banknotes so they're spotted wherever they turn up.
One limitation: lineage follows funds between wallets, but it goes dark at a centralized exchange. Once stolen money lands in an exchange's omnibus wallet, onchain tracing can't determine which customer withdraws it. At that point, only the the exchange's internal records can. This is why forensics work shifts from tracing to subpoenas at that point, and is why compliance teams try to quickly identify and flag suspicious funds flagging funds before they reach an off-ramp.
Tracking cost basis for accounting
Treasury teams often acquire the same asset at different prices over time.
The chain shows every purchase, but doesn’t preserve the purchase price associated with each unit. Without that information, realized gains, losses, and tax reporting become much harder.
With lineage, each acquisition can be labeled with its cost basis. As those assets move between wallets or are partially sold, the cost basis moves with them according to the chosen accounting rule (FIFO, LIFO, or another policy). This gives you tax- and audit-grade books for onchain holdings.
Attributing stablecoin supply to partners
Stablecoin issuance is often distributed through partners and pay incentives based on how much circulating supply each partner is responsible for.
But once the stablecoins start moving between wallets, the blockchain doesn’t know which partner originally introduced a particular stablecoin.
Lineage solves that by labeling tokens the moment they’re allocated to a partner. As those tokens move between wallets, the attribution moves with them, allowing issuers to calculate live partner balances instead of reconstructing them later.
This is the approach running behind Phantom’s $CASH, where every mint, transfer, and burn continues to carry its original partner attribution.
Why lineage is hard to compute
The idea behind digital asset lineage is straightforward: attach information to money, then keep that information attached as the money moves.
The hard part is making those labels stay correct.
Unlike balances or transfers, lineage isn’t something a blockchain records for you. Every answer has to be reconstructed by replaying the chain and maintaining additional state alongside it.
While real-time blockchain indexing is a hard problem to solve in its own right, reading the chain is just the starting point. Goldsky’s indexers lets you do this across 150+ EVM and non-EVM chains.
The hard part begins after you’ve indexed the chain. Doing that correctly at scale comes down to three challenges.
The information you care about isn’t onchain
You can’t look it up. The blockchain won’t tell you which partner originally issued a token, or that a wallet belongs to a sanctioned entity.
Those facts have to come from somewhere else. Usually you.
The first step is choosing an onchain event thatrepresents that fact (which we’ll later call the anchor) and then attach the label yourself before propagating it through every subsequent transfer.
Order isn't optional, and chains rewrite themselves
Ownership changes with every transfer, whether initiated by users or smart contracts. To know which labels make up a wallet’s balance, you have to process events in the exact order they happened. Getting the order wrong corrupts every calculation after.
Complicating things further, chains also reorg. Blocks you already processed get retracted, new ones replace them, and your lineage has to rewind and replay along with the chain.
The state is large and never stops moving
To know what each wallet holds by label, you maintain a running, labeled balance for every address that has ever touched the asset.
Every single transfer updates that state. For an asset with millions of holders, that’s a big, constantly changing dataset. Not something you can periodically recompute or cache once and forget.
The rest of this article shows how those three problems can be solved with a single streaming pipeline.
How to trace digital asset lineage (3 ways)
Teams today usually use one of three common methods to trace lineage within blockchain data: approximation, batch job, and real-time tracking. Unsurprisingly, each one trades fidelity for effort.
The difference is how faithfully they follow funds as they move. Some only track boundary events (like mints and burns). Some reconstruct lineage after the fact. The most complete approach follows funds in real-time as they move.
| Approximation | Batch recomputation | Real-time tracking | |
|---|---|---|---|
| How it works | Sum boundary events like mints and burns | Rebuild balances on a schedule | Statefully streams events in order and carries labels per transfer |
| What it tracks | Net supply per partner, boundary events only | Full balances, rebuilt each run | Labeled balances per address, updated continuously |
| Tracks funds as they move | No | Yes, as of the last run | Yes, live |
| Freshness | Current for net totals | Stale between runs | Live |
| Order and reorg correctness | Not needed | Not handled by default | Built in |
| Effort | Low | Medium | High to build, low if managed |
| Best for | Simple net payouts with no movement questions | Reconciliations, audits, reports | Live payouts, real-time risk, everything from batch |
1. Approximate lineage from mints and burns
The simplest and cheapest model is approximation.
For partner attribution, you’d book-keep only the boundary events: how much each partner minted, how much was burned, and the result netted into a per-partner supply number.
This works when the only question is “How much net supply should be attributed to each partner?”
It doesn’t involve state, propagation, or a query you can run. It works when payouts depend only on net supply attributable to a partner and nobody needs to know where specific funds went.
Because this method doesn’t track funds, it can’t answer questions like:
- Which partner's dollars are sitting in this wallet now?
- Did any of partner A's supply reach a sanctioned address?
- Which downstream wallets hold value from this source?
Those answers live in the transfers between boundary events, which this method doesn’t track.
2. Recompute lineage in batch jobs
The next step up is a scheduled job that recomputes lineage from scratch.
Teams that already pull onchain data into a warehouse like BigQuery, Snowflake, or ClickHouse reconstruct balances and walk the transfer graph to propagate labels, with recursive SQL, Spark, or custom jobs.
This is a good fit for backward-looking work where stale data is acceptable such as
- monthly close
- audit preparation
- historical reports
- one-off investigations
The downsides:
- the answer is always as stale as the last run
- full recomputation gets slower and more expensive as history grows
- correctness depends on replaying events in exact order and handling reorgs
3. Track lineage in real time with an indexer
The most complete approach is real-time tracking.
Tracking lineage in real time requires blockchain indexing plus a stateful engine on top: stream events in order, maintain a labeled balance for every address, and carry the label forward on every transfer.
This is the model used when teams need a current fund-level answer rather than a periodic report. It avoids the blind spots of approximation and the staleness of batch recomputation.
The hard part is operating it. You need ordered replay across chains, reorg rewinds, and continuously updated per-address state for assets with millions of holders. Most teams don’t want to build and run that infrastructure themselves.
With Turbo pipelines, this becomes a managed pipeline. You get the live lineage output without the months it takes to build ordering, reorg handling, and state management from scratch.
Note: Real-time tracking gives you the same output you’d want for batch reporting. Because Goldsky’s pipelines stream enriched events to your sinks of choice, one pipeline can support both live use cases like payouts and alerts, as well as backward-looking reporting for audits, reconciliations, and monthly close.
If a label isn’t onchain, how does it stay attached as money moves?
You replay every transfer in order while maintaining a running, labeled balance for every address. Whenever money moves, the labels move with it.
Every lineage system has three pieces:
- Anchor: where a label begins
- Rule: how labels propagate (move)
- State: what each address currently holds
1) The anchor: where a label starts
Although a label lives offchain, there's almost always an onchain event that acts like a proxy for it. We call that event the anchor.
For a stablecoin issuer, the anchor might be tokens leaving a known allocation wallet (the wallet the issuer uses to hand supply to partners). That transfer is effectively says:
“These tokens were issued to Partner A.”
That’s enough to label those tokens as Partner A
Other anchors work the same way:
- a sanctioned address →
tainted - a treasury account →
cost-basis lot - a bridge deposit →
origin: bridge X
Once a label has been created, the problem changes from labeling to propagation (keeping the label attached upon every subsequent transfer as the tokens move around).
2) The rule: how a label flows
So an anchor creates a label.
The rule determines what happens next.
Picture each address as a set of lots (batches), and every lot has a label and an amount. For example, a wallet might hold 100 USDC:
- 60 USDC is from partner A
- 40 USDC is from partner B
If that wallet sends 30 USDC, which partner does it come from?
There’s no onchain answer. Just like an accountant deciding which lot of shares you sold, you apply a rule.
Phantom $CASH uses FIFO (first in, first out).
Other systems might choose:
- LIFO (last in, first out)
- Proportional (every transfer draws proportionally from every label)
- Taint (a label never disappears and continues propagating indefinitely, so anything that touches a flagged address stays flagged)
Different use cases require different rules.
Compliance tracing often prefers taint propagation. Treasury usually uses FIFO or LIFO. Partner attribution may use FIFO or proportional allocation.
Note: fungible tokens don’t retain individual identity once balances commingle (mix) inside a wallet. FIFO, LIFO, and proportional are accounting conventions you impose on top of the transfers. The rule you pick defines the answer. Correctness means the rule is applied consistently and in exact order.
3) The state: a labeled balance for every address
To answer questions like:
- Which partner’s supply is in this wallet?
- Which funds originated from a sanctioned address?
- Which cost basis applies to this balance?
…you maintain a running balance for every address that has ever touched the asset, broken down by label, and update it on every transfer.
The chain can't tell you this because state only exists once you've replayed the whole transfer history in order according to your chosen rule.
Everything underneath is the same regardless of the use case. Whether you’re tracking partner attribution, sanctions exposure, cost basis, or source of funds, only two things change:
- Anchor: which events create labels
- Rule: how those labels propagage
The ordering, replay, and state management stay exactly the same.
Pools, swaps, and cross-asset lineage
Everything we’ve discussed so far assumes transfers of the same asset.
That covers most of a stablecoin's life, but two situations require additional rules:
- assets entering a pooling contract, like AMMs, lending protocols, or bridges
- assets being exchanged for a different token
Both cases break the simple assumption that the exact same units continue moving from wallet to the next.
When tokens enter a decentralized finance (DeFi) liquidity pool, they’re mixed with everyone else’s deposits. The tokens that come back out aren’t literally the same units that went in.
Likewise, when tokens are swapped for a different asset, the original asset is gone. If lineage is supposed to answer “where did this value come from?”, what should happen to the partner attribution?
There isn’t a single universally correct answer.
Instead, you define another propagation rule.
- For some use cases like partner attribution, it’s perfectly reasonable to end the lineage when the original asset leaves circulation. Treating a swap as supply leaving is usually enough. Once $CASH becomes USDC, the partner attribution has served its purpose.
- For others—like compliance or transaction tracing—you may want the lineage to continue across the swap, allowing the resulting USDC to inherit the original blockchain provenance.
The important point is that this isn’t a limitation of the pipeline. It's a modeling choice you make, the same as picking the rule.
Once you’ve defined how lineage should behave across pools, swaps, or bridges, the same ordered replay and state machinery applies exactly as before. The algorithm doesn’t fundamentally change; only the propagation rule does.
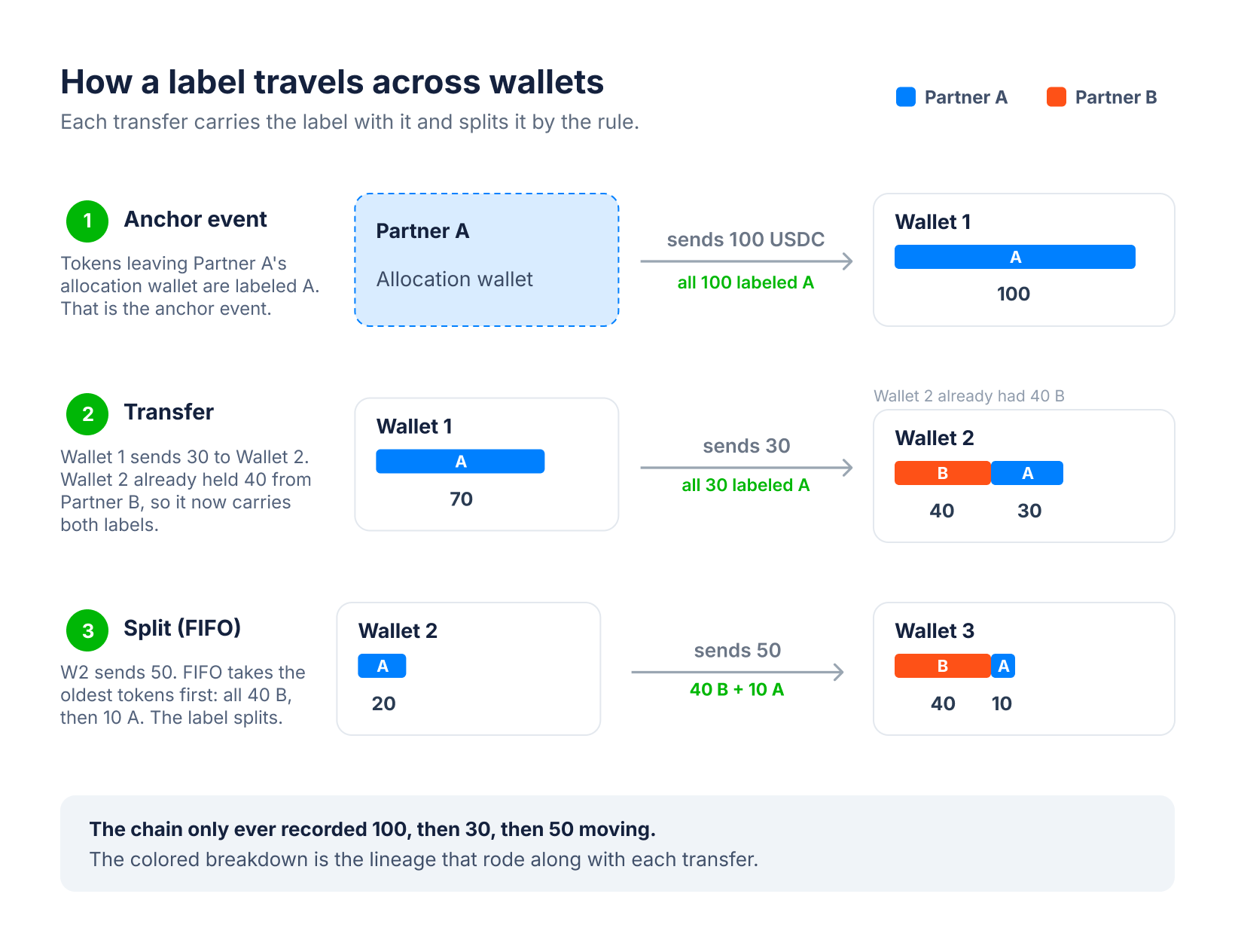
Running lineage with a single streaming pipeline
Earlier we broke every lineage system down into three primitives:
- Anchor: where a label begins
- Rule: how labels propagate (move)
- State: what each address currently holds
The same idea maps directly onto a streaming pipeline:
- a source delivers ordered blockchain events
- a transform applies the anchor, rule, and state logic
- a sink writes enriched events wherever you keep your data
The architecture of a stateful label-propagation pipeline. Teal marks label state; purple is the engine. An ordered, reorg-aware multichain source and a label set feed a label-propagation transform that maintains labeled balances and emits each event enriched with a per-label attribution field.
Getting events in the right order: the source
The source is the foundation. Everything that follows depends on replaying events in exactly the order they happened: block → transaction → instruction → inner instruction.
If events arrive out of order, every balance after that point becomes wrong.
That’s why the source guarantees ordering across Solana, Stellar, Bitcoin, and every other supported chain. Rather than silently producing incorrect output, the pipeline halts if event order can no longer be guaranteed
The source also handles chain reorganizations. When the chain retracts blocks, previously emitted events are retracted too, allowing the lineage engine to rewind its state and replay the canonical chain to match.
Applying lineage: the transform
The transform is where the labeling logic lives. You configure its behavior.
The transform applies:
- the anchor (where labels begin)
- the propagation rule (how labels move)
- the state updates (what every address holds after each transfer)
It also maintains two different kinds of state:
- The label set: maps addresses to labels (e.g. sanctioned wallets). It’s small, rarely changes, and sits behind a pluggable backend like Postgres. Updating the label set doesn’t require redeploying anything.
- The derived state: the continuously changing per-address, per-label balances that mutate on every transfer. Again, stored where you want (Postgres, an embedded store, or your own database), so the balances are queryable right inside your pipeline.
Because the whole topology runs in a single process on Streamling, every event flows through one stateful step without requiring distributed coordination. The per-address state can still scale independently through the pluggable backend.
Sending enriched events where you need it: the sink
The sink writes enriched events to wherever your data already lives: Snowflake, ClickHouse, Postgres, or any other destination supported by Turbo.
Lineage becomes another dimension in your existing warehouse, ready for dashboards, reports, payouts, alerts, or downstream applications.
What this looks like in practice
Once you’ve defined the anchor, propagation rule, and storage backends, the entire pipeline is just configuration.
sources:
instructions:
type: solana_instructions # ordered, reorg-aware source
dataset_name: phantom_cash.cash_instructions
start_at: earliest
transforms:
label_propagation:
type: goldsky.label_propagation
from: instructions
primary_key: instruction_id
options:
rule: fifo # fifo | lifo | proportional | taint | custom
labels: # the label set: addresses -> labels
backend: postgres # in-memory | postgres | redis
entity: cash_labels # updates take effect going forward
state: postgres # derived (address, label, amount) balances
sinks:
labeled_output:
type: clickhouse # This can go into any database Turbo supports
from: label_propagation
table: yield_tracking_output
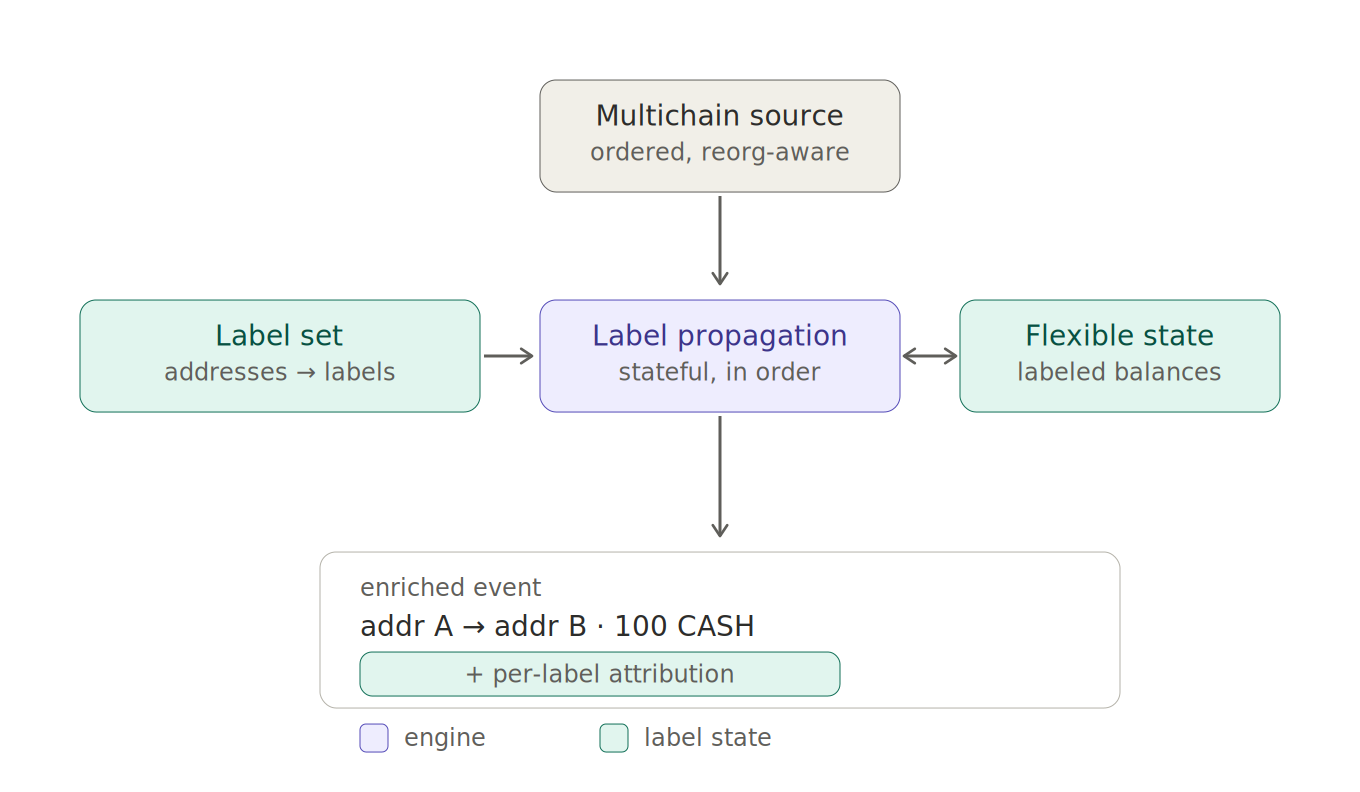
primary_key: instruction_idWhat comes out of the pipeline
After all that replay, state management, and propagation, the output is simple. Every transfer carries one additional field that wasn’t present onchain.
Onchain versus pipeline-enriched event. On chain, a transfer records only that 100 CASH moved from address A to address B, with owner and origin not recorded. With the pipeline, the same transfer carries an added dimension: partner A 60 and partner B 40. The chain records the movement. The pipeline records the movement plus the dimension.
Every transfer comes out carrying a field that didn’t exist before. “100 CASH moved from A to B” will also carry how much of it belonged to each label. That field is simply a read of the state the engine maintains, which is why it’s the same color in the architecture diagram.
One engine, many kinds of lineage
Throughout this article we’ve used partner attribution as the running example. But the engine doesn’t know (or care) what the label represents.
Once you’ve defined the anchor and the propagation rule, the same machinery works for many different problems.
| Use case | The anchor | The rule | What you can answer |
|---|---|---|---|
| Partner attribution | Tokens leaving an allocation wallet | FIFO | How much live supply traces to each partner |
| Deposit attribution | A customer deposit into a shared wallet | FIFO | Whose funds make up a commingled (omnibus) balance |
| Cost-basis accounting | Each acquisition, at its price | FIFO or LIFO | Realized gains for tax- and treasury-grade books |
| Compliance tracing | A hacked or sanctioned wallet | Taint | Where a flagged wallet's funds ended up, hops later |
| AML risk scoring | A mixer, darknet market, or ransomware wallet | Proportional taint (risk dilutes as it mixes with clean funds) | What share of a wallet's balance carries high-risk provenance |
| Cross-chain origin | Tokens arriving through a specific bridge | Proportional | How much supply on this chain came across which bridge |
| Yield attribution | Principal a customer deposits into a yield product | FIFO, time-weighted | How much interest or staking rewards to credit each customer |
| Proof of reserves | Tokens issued against a specific reserve lot | Proportional | Which reserves back the tokens in circulation |
Make money move
Digital asset lineage is the missing layer between blockchain transfers and financial systems.
Whether you’re issuing a stablecoin, tracing distributions, or building payment infrastructure, the underlying problem is still the same: “How do you keep information attached to money after it moves?”
If you’re building products where onchain accounting matters, we’d love to help. Read the $CASH case study, explore Turbo Pipelines and Streamling, or start for free.