Unlocking the secrets of onchain data - Coinbase Developer Podcast
In this episode, Jeff chats with Yuga Cohler and Erik Reppel from Coinbase about how to smooth out the rough edges of blockchain data indexing, streaming tech, how to build a blockchain with good data, and more.

Chief Technology Officer
In this episode of CDPod, the Coinbase Developer Podcast, Goldsky co-founder and CTO Jeff Ling joined fellow engineers Yuga Cohler and Erik Reppel to discuss what it takes to make blockchain data usable at production scale, from subgraphs and multichain indexing to reorg handling, streaming pipelines, and the future of onchain applications. We've organized and expanded it for clarity. Watch the podcast on YouTube.
What is blockchain indexing?
Blockchain indexing is the process of turning raw blockchain data into structured, queryable data.
A blockchain node contains the source data, but not usually in the shape your product wants. It’s optimized for consensus and execution, not for rendering a beautiful app UI.
An indexer sits between the chain and the application. It reads blocks, transactions, logs, traces, or events, applies decoding and business logic, and stores the result somewhere easier to query.
That might be a GraphQL API. It might be Postgres. It might be Kafka, ClickHouse, a webhook, a data warehouse, or some internal backend service.
The point is the same: the chain tells you what happened, but the indexer turns that into product-ready data.
Why blockchain data indexing is harder than it looks
Onchain data is public. That’s one of crypto’s biggest strengths. But public doesn’t mean usable.
Every swap, transfer, mint, loan, vote, bridge transaction, and contract interaction may live onchain, but that doesn’t automatically give you a clean API, a fast dashboard, a reliable activity feed, or a real-time notification system.
That’s where indexing is useful. For simple apps, you might get away with calling an RPC endpoint and reading contract state directly. But once you need historical data, charts, feeds, aggregates, search, alerts, or anything close to a polished user experience, you need something more durable.
You need a way to listen to the chain, extract the data that matters, transform it, handle edge cases, and serve it back in a form your app can actually use.
"When I was the Head of Engineering at Zora, probably at least 30% of our engineering effort went into indexing." — Erik Reppel, Head of Engineering @ Coinbase Developer Platform, creator of x402
This is the hidden data engineering behind great onchain products.
Why is Web3 indexing different from Web2 indexing?
Indexing isn’t unique to crypto.
Search engines index the web. Data platforms index documents, transactions, logs, and events. Large Web2 companies deal with massive data pipelines all the time.
The difference in Web3 is that the source data has its own weirdness.
The data is public, but the path to getting clean data can be messy. Nodes can lag. RPC providers can behave differently. Caches can return confusing results. Chains can reorganize. Different networks expose different data models. And the “current” chain tip is always moving.
So the hard part isn’t just reading data.
The hard part is reading it reliably, correcting it when needed, normalizing it across chains, and giving developers an interface that doesn’t force them to care about every underlying edge case.
A good indexing system absorbs a lot of that complexity.
Why do crypto apps need indexers?
At the beginning, a dapp might not need much indexing.
If all you’re doing is submitting a transaction and showing the result, you can often read directly from the chain. A swap modal, for example, can wait for a transaction to confirm and display the output.
But more complex products need to answer bigger questions:
- What has this wallet done over time?
- How much volume did this pool process today?
- What’s the user’s full transaction history?
- Which NFTs changed ownership?
- What happened across multiple chains?
- Which events should trigger a notification?
- What data should appear in a chart, feed, or leaderboard?
Those questions are hard to answer with direct RPC calls alone. You need a system that has already processed the raw chain data and organized it around the way your application thinks.
That’s why indexing can quietly become a huge chunk of engineering work. It’s not always the most visible part of the product, but it often determines whether the product feels fast, accurate, and reliable.
What is a subgraph?
A subgraph, popularized by The Graph, is one of the most common ways crypto teams start indexing onchain data.
You define the smart contracts and events you care about, write mapping logic, and expose the processed data through an API, often GraphQL. Instead of building a whole indexing stack from scratch, you get a framework for turning contract events into queryable entities.
That’s why subgraphs became such a core part of the industry. They let teams move quickly. They’re also portable, familiar, and widely used across protocols.
For a lot of teams, the progression looks something like this:
- First, read directly from contracts.
- Then, use events and logs.
- Then, deploy a subgraph.
- Then, once the app gets big enough, start running into the limits of that model.
Subgraphs are a great starting point. They’re not always the final form.
When do teams outgrow subgraphs?
Teams usually start to feel subgraph limitations when they need more speed, more scale, or more control.
A subgraph works well when the indexing logic can run in a relatively straightforward sequence: see an event, update the database, move to the next relevant event.
That simplicity is part of the appeal.
But some workloads don’t fit that pattern well. If you’re indexing a very high-volume contract, doing analytics across an entire chain, handling dense data from a fast network, or trying to power a real-time experience, sequential processing can become a bottleneck.
At that point, the problem starts to look more like traditional data engineering.
You start thinking about parallel workers, queues, Kafka topics, Flink jobs, stream processing, transformations, consumer groups, partitioning, backfills, and downstream databases.
That’s a very different world from “just give me a GraphQL API.”
What makes reorgs so painful?
Chain reorganizations (reorgs) are one of the classic blockchain data problems.
A block can appear to be part of the canonical chain, then later get replaced. The transactions might still land somewhere else, but their ordering, block hash, or surrounding metadata can change.
For a real-time system, that’s painful because you may have already sent the old data downstream.
Maybe it’s already in a user’s database. Maybe it already powered a notification. Maybe it already updated an analytics table.
Now the system has to say, “Actually, that version of history is no longer valid.”
That’s where careful data modeling matters.
Instead of blindly inserting rows, indexers often need to upsert records, track where each record came from, and include enough metadata to invalidate or correct stale data later.
For EVM-style logs, that means thinking carefully about identifiers like chain ID, block hash, transaction hash, and log index. The exact strategy can vary, but the core idea is simple: when the chain corrects itself, your data system needs a clean way to correct itself too.
Why upserts matter for onchain data
In normal application development, inserting a row can be enough.
With blockchain data, especially real-time blockchain data, inserts alone can get you into trouble.
If a block gets replaced, or if the same event is seen again through a different path, you don’t want duplicate or stale records. You want deterministic keys and predictable updates.
That’s why upserts come up so naturally in indexing. You’re not just adding data forever. You’re maintaining a view of what the chain currently says is true.
The trick is choosing keys that survive the weirdness of chain data.
- Too little metadata and you can’t fix bad records.
- Too much complexity and every downstream developer has to become an indexing expert.
The best systems find a practical abstraction: enough information to handle reorgs and corrections, without making every app team write custom reorg logic.
Why multichain indexing is hard
Supporting one chain is already a lot of work.
Supporting hundreds of chains is a different problem.
Even among EVM chains, there can be differences in RPC behavior, node reliability, block times, indexing requirements, and ecosystem tooling. Once you move beyond EVM, the differences get bigger.
Solana, Cosmos chains, Sui, Aptos, Stellar, Arweave, and other ecosystems don’t all expose data in the same way. Some have different transaction models. Some have different finality assumptions. Some have different event structures. Some require custom adapters before the data can even enter the same pipeline.
That’s why multichain indexing isn’t just “add another RPC URL.”
For a familiar chain type, adding support can be mostly configuration. For a new architecture, it may require new adapters, new normalization logic, and new testing.
The goal is to let developers work with a consistent interface without flattening away the parts of each chain that actually matter.
Why EVM chains are often easier to index
EVM chains have a big advantage: tooling.
There are well-understood concepts like blocks, transactions, logs, traces, receipts, contract events, chain IDs, and RPC methods. There’s also a large ecosystem of libraries, infrastructure providers, and developers who already know how to work with them.
That doesn’t mean EVM indexing is easy. Reorgs, RPC inconsistencies, high-volume contracts, and fast chains can still create plenty of pain.
But compared with a brand-new data model, EVM has a lot of shared vocabulary.
If you’re building an indexer, shared vocabulary matters. It means fewer surprises, more reusable components, and a faster path from raw chain data to something developers can build with.
What makes a chain easier to index?
The best chains don’t treat indexing as an afterthought. They give developers and infra providers clear specs, predictable data structures, stable APIs, useful test cases, and reference transactions before launch.
If a chain has simple structures and clear documentation, indexers can support it quickly. If the node behavior is inconsistent or the data model is unclear, every downstream team pays for that complexity.
Good chain design isn’t just about execution speed or fees. It’s also about how easy it is for the ecosystem to understand what happened.
Because if wallets, explorers, analytics tools, games, DeFi apps, and AI agents can’t easily read the data, the developer experience suffers.
How does Goldsky add new chains?
For familiar chain types, adding support can be surprisingly lightweight.
If the indexing system already understands the chain family, a new network may be mostly configuration: RPC details, chain metadata, data source settings, QA checks, and deployment.
For new chain types, there’s more engineering work. You may need to write an adapter, normalize the data, test edge cases, and make sure the new source fits into the existing pipeline.
The interesting part is the abstraction layer.
A good indexing platform needs to support many different chains without making the rest of the system care about every difference. That means turning chain-specific data into normalized streams that can be transformed, filtered, and delivered to customers.
Some of that is elegant architecture.
A lot of it is just grinding through edge cases.
That’s the not-so-secret truth of good data engineering: there usually isn’t one magic trick. There are a thousand small decisions that make the system more reliable over time.
Why streaming matters for onchain apps
A lot of onchain products need data as soon as possible.
Not eventually. Not after a batch job runs. As close to real time as the system can reasonably get.
That’s especially true for trading apps, prediction markets, games, notifications, dashboards, and user-facing activity feeds.
Streaming pipelines are built for that world. Instead of waiting for periodic batch jobs, data moves continuously from the chain into downstream systems.
That sounds simple, but under the hood there are a lot of choices to make.
- How do you split data across topics?
- How many workers do you need?
- Where should a new consumer start reading?
- How long should data be retained?
- How do you handle backfills?
- How do you avoid making every customer understand Kafka, Flink, offsets, partitions, and consumer groups?
The best user experience hides most of that. Developers should be able to say what data they want, where it should go, and what transformations they need. The platform can handle the messier details behind the scenes.
Batching vs. streaming
Batching and streaming are both useful, but they create very different developer experiences.
Batching is efficient for historical data. If you need to process millions or billions of old records, batch jobs can be cheaper and faster.
Streaming is better for live systems. If your app needs to react as data arrives, you don’t want to wait for a batch job.
The hard part is that blockchain apps often need both.
You need historical data from the beginning of a contract or chain. But you also need live data from the current tip. And somehow those two paths need to meet cleanly.
That handoff is where a lot of complexity lives.
Zeno’s paradox, but for blockchain data
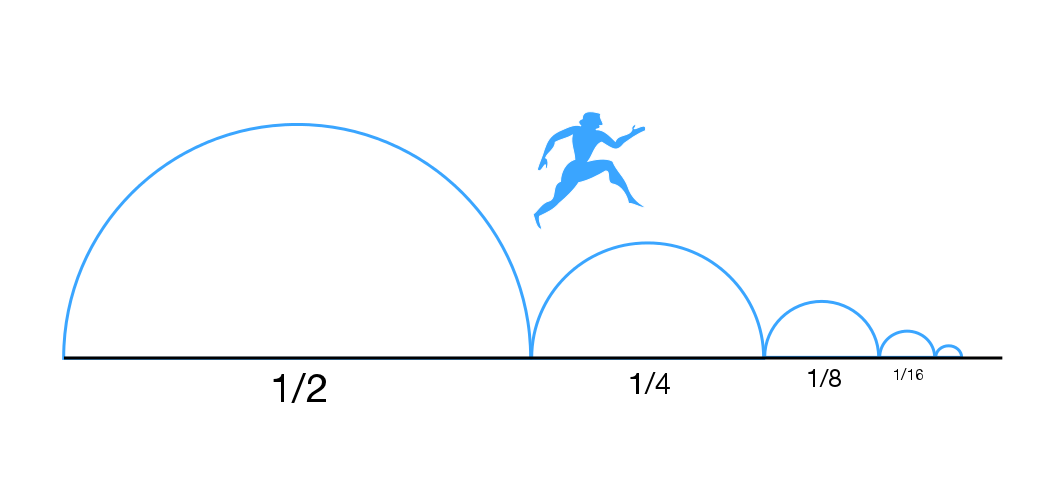
There’s a funny way to think about backfills.
Say the current chain tip is block 100. You start backfilling from the beginning to block 100.
But while you’re doing that, the chain keeps moving.
By the time you reach block 100, the tip is now block 150. So you process up to 150. But now the tip is 180. Then 195. Then 205.
You’re always catching up to something that keeps moving away from you.
That’s basically Zeno’s paradox for blockchain data.
In practice, systems solve this by coordinating backfills with live streaming. You might snapshot a tip, backfill to that point, then switch to live data. Or you might build a pipeline that makes the whole thing look like one continuous stream.
The important thing is that developers shouldn’t have to reinvent that logic every time they build an app.
Why the best data infrastructure feels boring
The ideal data product doesn’t make developers think about reorgs, backfills, RPC quirks, partitioning, or edge streaming all day.
It just works.
That’s the funny thing about infrastructure. When it’s bad, everyone notices. When it’s good, it disappears into the background.
For crypto to feel mainstream, a lot more of the infrastructure needs to disappear into the background.
Developers should be able to focus on the product: the game, the trading experience, the wallet, the marketplace, the payment flow, the protocol.
Not the fifteenth weird indexing bug they had to debug that week.
What’s next for onchain apps?
One of the most encouraging trends is that more crypto apps are starting to feel like real products.
Not just speculative interfaces or assets you can trade. Actual payments, apps, and experiences where blockchain is part of the system instead of the entire point of the system.
Lower fees help. Faster chains help. Better wallets help. Stablecoins help. Better developer tools help.
But data infrastructure is a huge part of that story too.
If onchain apps are going to feel instant, reliable, and useful, they need data systems that can keep up.
Where payments fit in
Payments are another area where crypto is starting to feel more practical.
The example that came up was API payments: instead of creating an account, adding a credit card, dealing with cross-border fees, and managing credits manually, what if software could pay for usage directly?
That’s the kind of use case where crypto can make something meaningfully simpler.
And when payments, apps, agents, and onchain data start to connect, the data layer becomes even more important. More activity means more events. More events mean more indexing. More indexing means more need for reliable, real-time infrastructure.
Key takeaways
- Onchain data is public, but it still needs to be indexed before most applications can use it well.
- Subgraphs are a great starting point for many teams, especially when they need a structured API for contract data.
- Teams start to outgrow subgraphs when they need more speed, scale, parallelism, real-time delivery, or custom data destinations.
- Reorgs are one of the hardest parts of blockchain indexing because real-time systems may need to correct data they’ve already sent downstream.
- Upserts, deterministic keys, and metadata are essential for keeping onchain data accurate.
- Multichain indexing is hard because every ecosystem has different data models, APIs, and edge cases.
- Streaming pipelines make onchain apps feel faster, but they hide a lot of complexity under the hood.
- Backfills are tricky because the chain tip keeps moving while you’re trying to catch up.
- The best infrastructure lets builders focus on the product instead of becoming full-time data engineers.